Why not just give the entire document to the LLM?
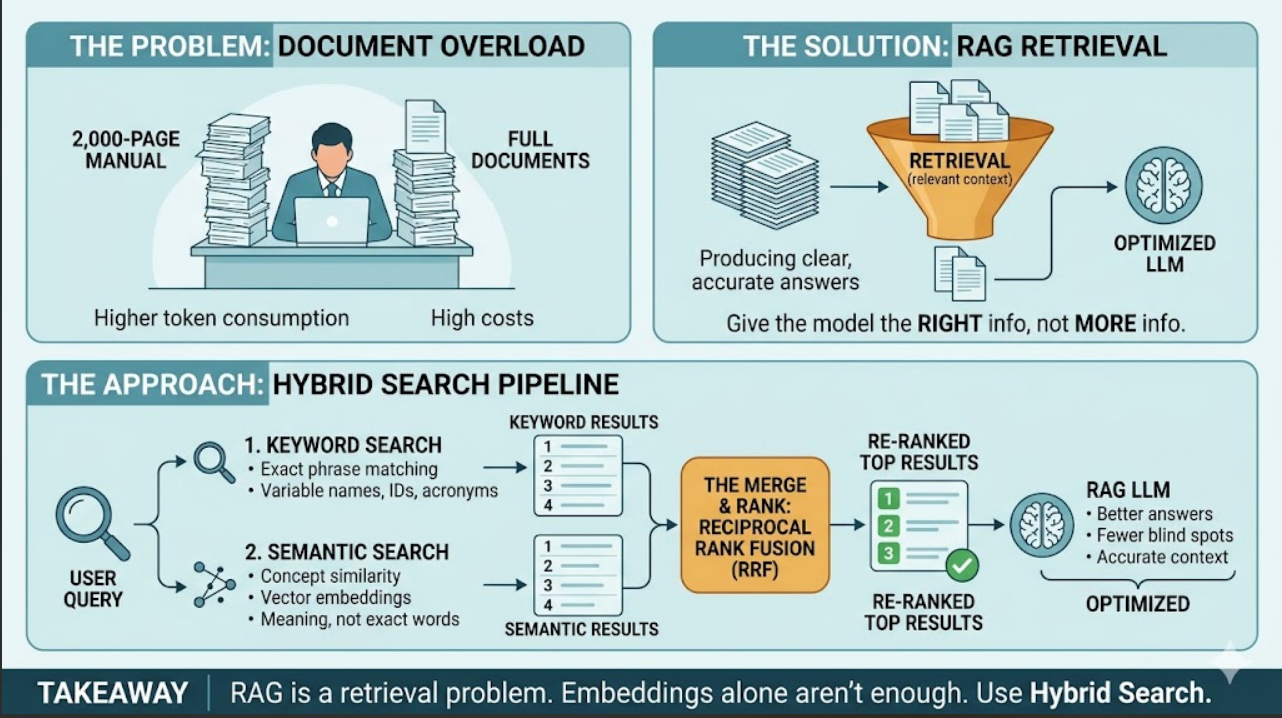
More information doesn't always mean better answers. RAG solves this by retrieving only the most relevant context for the LLM. But keyword search and semantic search each have blind spots. The solution? Use both with Reciprocal Rank Fusion.
The Problem
Sending entire documents to an LLM increases token costs and reduces answer quality. RAG retrieves only the relevant context, but choosing between keyword search and semantic search means trading off exact matches against intent-based matching.
The Solution: Hybrid Search
Run keyword search and semantic search in parallel, then merge results using Reciprocal Rank Fusion (RRF). Documents found by both methods get a ranking boost, giving you better retrieval quality with fewer blind spots.
Takeaway
RAG is fundamentally a retrieval problem, not a vector database problem. Embeddings are useful, but retrieval quality depends on combining keyword search, semantic search, and ranking strategies.
Key Takeaway: Don't choose between keyword and semantic search. Use both. The improvement is noticeable from day one.